9.1. Clustering Algorithms - \(k\)-Means#

9.1.1. \(k\)-Means#
The aim of clustering algorithms is to group data points based on a defined similarity measure (and this is crucial!). Here we will use the clustering algorithm \(k\)-Means. An algorithm that divides a given (even high-dimensional) data set into \(k\) groups (clusters).
K-means is the go-to unsupervised clustering algorithm, whcih is easy to implement and trains in next to no time. As the model trains by minimizing the sum of distances between data points and their corresponding clusters, it is relatable to other machine learning models.
%load_ext lab_black
# First, let's import all the needed libraries.
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
from sklearn.cluster import KMeans
import warnings
warnings.filterwarnings("ignore", "use_inf_as_na")
9.1.1.1. Introduction#

\(k\)-Means clustering is an unsupervised algorithm that groups unlabelled data into different clusters. The K in the title shows how many clusters will be created. It’s important to know this before you start training the model. So, if we use K=3, we’ll get three clusters. The \(k\)-Means algorithm is used in fraud and error detection, and confirming existing clusters in the real world.
The algorithm is centroid-based, which basically means that each data point is assigned to the cluster with the closest centroid. You can use this algorithm for any number of dimensions, because we calculate the distance to centroids using the Euclidean distance. The idea behind \(k\)-Means is to make the distances between the data points and their assigned cluster centroid as small as possible. This is done by repeatedly moving data points to the closest centroid and centroid to the centre of their assigned points, which makes the clusters more compact and separated.
The great thing about the \(k\)-Means algorithm is that it’s simple to use, it can handle huge datasets, it always converges, and it works well with clusters of varying shapes and sizes. The drawbacks are that the number of clusters has to be chosen manually, the clusters are dependent on initial values, and it can be sensitive to outliers.
9.1.1.2. Performing \(k\)-Means Clustering#
The algorithm works as follows (somewhat simplified):
Choose a cluster number \(k\) and select \(k\) cluster centres (centroids) for initialisation. These centroids can be randomly distributed in the state space or elements can simply be randomly drawn from the training data set to serve as centroids. (Initialisation)
assign each data point to the cluster whose cluster centre (centroid) is closest to this point. ‘Closeness’ is determined by the distance measure, which can be Euclid’s distance, for example, which is calculated with the following equation:
recalculate all \(k\) cluster centres: The mean value (in all dimensions) of all data points in a cluster results in the new cluster centre (centroid).
cancellation criterion fulfilled? (e.g. ‘maximum number of iterations reached’ or ‘cluster centres change only slightly’) Otherwise go to 1.
For the sake of simplicity, we use simulated data in this exercise:
cluster_df = pd.read_csv("data/cluster_sample_data.csv", header=None, sep=" ")
cluster_df.head(3)
| 0 | 1 | |
|---|---|---|
| 0 | 5.209759 | 4.191962 |
| 1 | -0.550619 | 1.731674 |
| 2 | 1.990295 | -1.352535 |
sns.scatterplot(
data=cluster_df,
x=0,
y=1,
)
<Axes: xlabel='0', ylabel='1'>
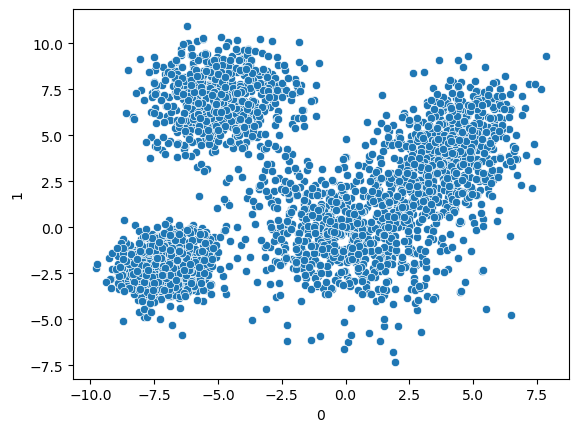
Question: Even without \(k\)-Means clustering, how many clusters would you suggest ?
9.1.1.2.1. Normalisation#
Before applying a clustering algorithm, it’s crucial to normalize the data to eliminate any outliers or anomalies.
cluster_df.iloc[:,0].values
array([ 5.20975935, -0.55061918, 1.99029538, ..., -6.58641027,
-7.71718373, -0.91433376])
from sklearn import preprocessing
#df_norm = cluster_df.copy()
#df_norm[0] = preprocessing.normalize([cluster_df[0]]).flatten()
#df_norm[1] = preprocessing.normalize([cluster_df[1]]).flatten()
#df_norm.head()
9.1.1.2.2. Determine the number of clusters (K=?)#
Elbow-method The optimal value of \(k\) in the \(k\)-Means algorithm can be found using the elbow method. This involves finding the inertia value of every \(k\) number of clusters from 1-10 and visualizing it.
Inertia: the sum of the squared distances of samples to their closest cluster center.
We iterate the values of \(k\) from 1 to n and calculate the values of distortions for each value of k and calculate the distortion and inertia for each value of \(k\) in the given range.
def elbow_plot(data,clusters):
inertia = []
for n in range(1, clusters):
algorithm = KMeans(
n_clusters=n,
init="k-means++",
random_state=125,
)
algorithm.fit(data)
inertia.append(algorithm.inertia_)
# Plot
plt.plot(np.arange(1 , clusters) , inertia , 'o')
plt.plot(np.arange(1 , clusters) , inertia , '-' , alpha = 0.5)
plt.xlabel('Number of Clusters') , plt.ylabel('Inertia')
plt.show();
elbow_plot(cluster_df,10)
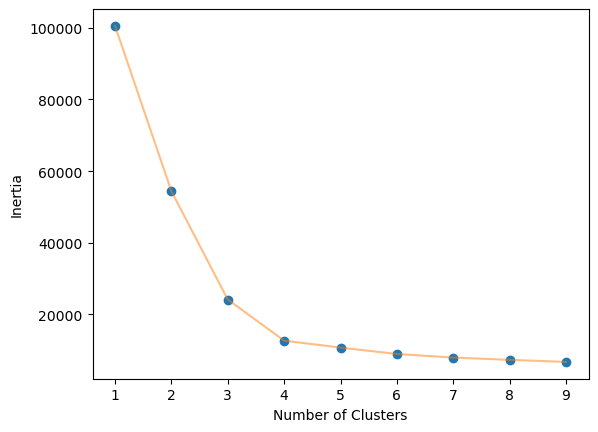
We obtained an optimal value of 4. Perfect, thats what we also suggested!
9.1.1.2.3. Performing \(k\)-Means#
As we already discussed we perform \(k\)-Means by initializing cluster centroids, assigning these data points to clusters. We then update cluster centroids and Iteratively update the centroids. In Python we perform \(k\)-Means as follows:
n_clusters = 4
epochs = 100
algorithm = KMeans(n_clusters=n_clusters,init="k-means++",max_iter=epochs,random_state=120 )
algorithm.fit(cluster_df)
labels = algorithm.labels_
for k in algorithm.cluster_centers_:
print(k)#algorithm.cluster_centers_
[4.08395992 4.23678392]
[-6.9494335 -1.9918705]
[-4.89561517 6.93335092]
[ 0.20879334 -0.47995951]
# The number of iterations required to converge
algorithm.n_iter_
7
algorithm.labels_
array([0, 3, 3, ..., 2, 1, 3], dtype=int32)
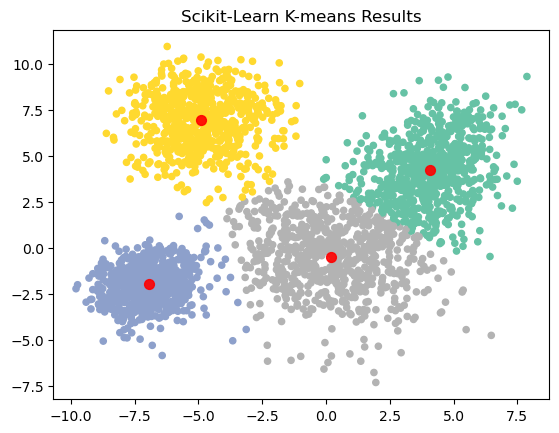
9.1.1.3. Assign data points to clusters and plot final Result#
y_kmeans = algorithm.predict(cluster_df)
plt.scatter(cluster_df.iloc[:, 0], cluster_df.iloc[:, 1], c=y_kmeans, s=20, cmap="Set2")
centers = algorithm.cluster_centers_
plt.scatter(centers[:, 0], centers[:, 1], c='red', s=50, alpha=0.9);
plt.title("Scikit-Learn K-means Results")
Text(0.5, 1.0, 'Scikit-Learn K-means Results')
Exercise
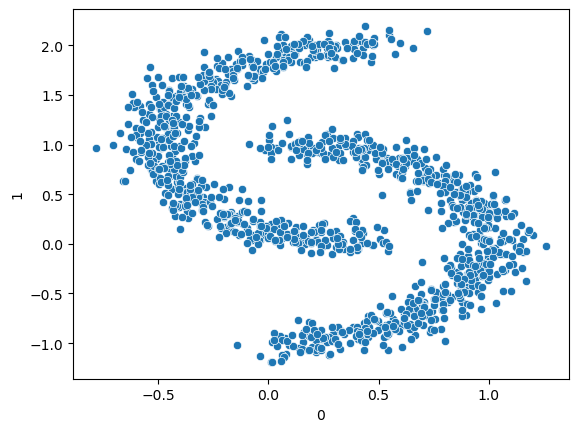
Take a look at another data set. Visualise the data as a scatterplot. How many cluster centres can be expected? Why does \(k\)-Means clustering not work well here? What are the limitations of \(k\)-Means?
cluster_df = pd.read_csv("data/cluster_sample_data_moons.csv", header=None, sep=" ")
cluster_df.head(3)
| 0 | 1 | |
|---|---|---|
| 0 | 0.890330 | 0.449208 |
| 1 | 0.927276 | 0.079686 |
| 2 | 0.176013 | 0.902117 |
9.1.1.3.1. solution#
sns.scatterplot(
data=cluster_df,
x=0,
y=1,
)
<Axes: xlabel='0', ylabel='1'>
### normalize
from sklearn import preprocessing
df_norm = preprocessing.normalize(cluster_df)
## elbow plot
elbow_plot(df_norm,10)
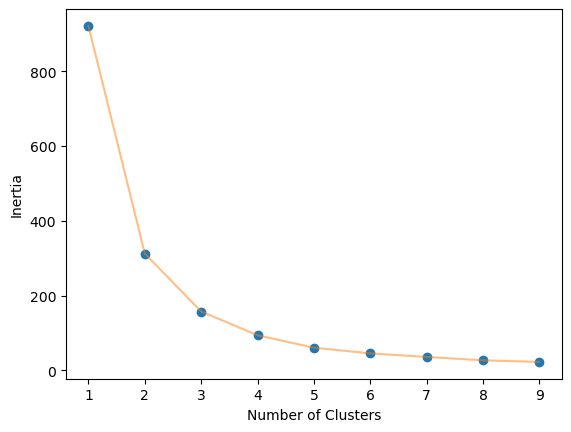
n_clusters = 2
epochs = 100
algorithm = KMeans(n_clusters=n_clusters,n_init='auto')#, init="k-means++",max_iter=epochs,random_state=120) # init="k-means++"
algorithm.fit(df_norm)
labels = algorithm.labels_
algorithm.n_iter_
5
sns.scatterplot(data = cluster_df, x = 0, y = 1, hue = labels, palette="Set2");
plt.title("Scikit-Learn K-means Results")
Text(0.5, 1.0, 'Scikit-Learn K-means Results')
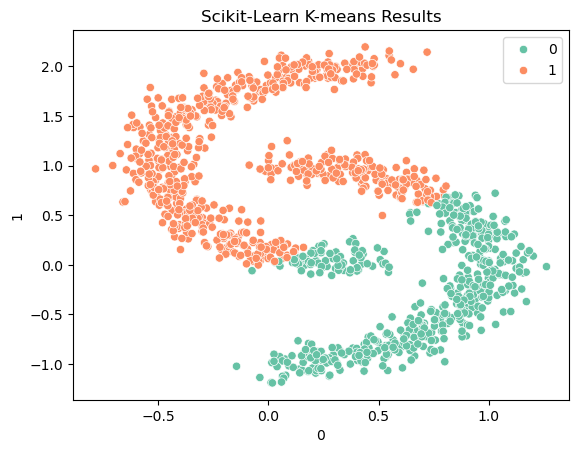
\(k\)-Means clustering may not work well in this case because the data points in the two clusters are unevenly distributed. \(k\)-Means is based on the assumption that the clusters are spherical and of similar size. If this assumption is not met, clustering can produce poor results.
\(k\)-Means is limited to linear cluster boundaries
Exercise
Research an alternative to \(k\)-Means that could work here! Can you even implement it with plot?
9.1.1.3.2. solution#
A possible alternative that could work better is the so-called ‘DBSCAN’ (Density-Based Spatial Clustering of Applications with Noise). DBSCAN is based on the density of data points and can identify clusters even if they are not spherical or of similar size.
9.1.1.3.3. Ressources for this script:#
from IPython.display import IFrame
IFrame(
src="../../citations/citation_marie.html",
width=900,
height=200,
)